
Pythonってホントになんでも簡単にできるなー、というわけで、今度は日本語の文章の解析です。実はいままでにもJavaやPHPなどで挑戦しては挫折してきたのですが(苦笑)、今ならできるかも…?
いろいろインストール
Windows 10 Home (64bit版) + Python 3.9.6 (64bit版) の環境で実験しています。
MeCabのインストール
ダウンロード&インストール
Pythonで独自に構文解析エンジンを作るのは大変すぎるので、この分野の定番・MeCabという日本語形態素解析エンジンをインストールして使うことにします。MeCabはオープンソースで、フリーで使用することができます。公式サイトはこちら。
公式サイトの下の方に
Binary package for MS-Windows
mecab-0.996.exe:ダウンロード
というリンクがあるので、ダウンロードします(2021.10時点でバージョンはmecab-0.996です。履歴によると2013年2月から更新されていないようです)。
ダウンロードができたら、mecab-0.996.exe を実行してインストールしましょう。
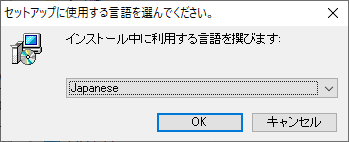
デフォルトの Japanese でいいでしょう。まぁMeCabを使おうとしている人は高確率で日本語がわかる人でしょうし…。
『次へ』以外に選択肢がないですね。
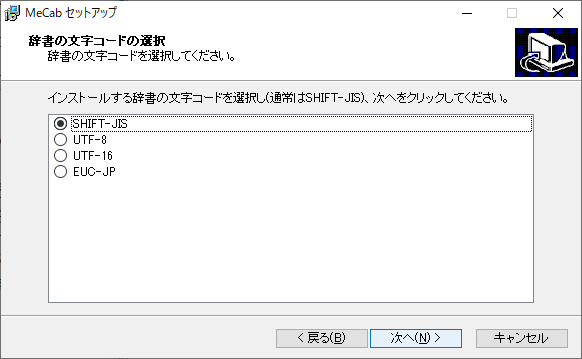
次の画面では文字コードの選択肢が出てきます。初期状態では Shift-JIS にチェックが入っていますが、Pythonのデフォルトの文字コードにあわせて UTF-8 に変更します(ただしUTF-8にするとコマンドプロンプトから使う時に文字化けするようになってしまいます)。
使用許諾契約書に目を通して、問題なければ『同意する』を選択して『次へ』。
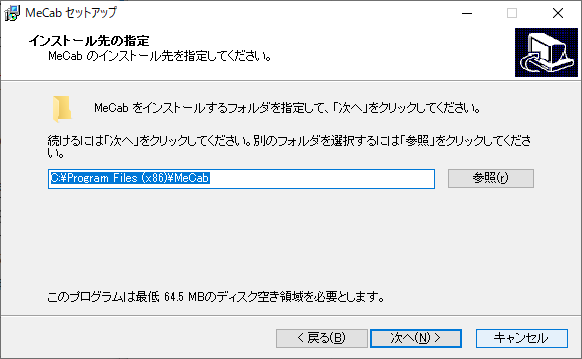
インストール先の指定。デフォルトだと C:\Program Files (x86)\mecab になっています。必要な容量は110MBほどのようです。インストール先のPATHは、後で環境変数を変更する際に必要なので、メモしておいて下さい。
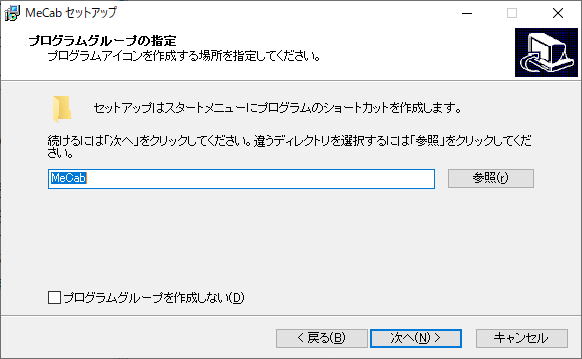
スタートメニューで表示されるショートカット名です。デフォルトは MeCab ですがお好みで。
最終確認です。『インストール』をクリック。
ファイルのコピーが始まります。
管理者権限のあるユーザで実行していると、このダイアログが表示されます。
まぁどちらでもお好みで。
Windows版には辞書が付属していますので、MeCab本体に続いて辞書がセットアップされます。
コマンドプロンプトが開いて、いろいろファイルが読み込まれている様子が表示されます。
手元の環境では1分もかかりませんでした。
ここまでくれば無事完了です。
※なお、Python 64bit版+MeCab 32bit版だと動かない、と言う情報をみかけたのですが、いまのところうちの環境ではPython64bit版+MeCab32bit版でちゃんと動作しているようです。
※公式サイトで配布されているのは32bit版のみです。
環境変数の設定
MeCabのインストーラはPATHの設定をしてくれないようなので、手動でPATHを追加します。
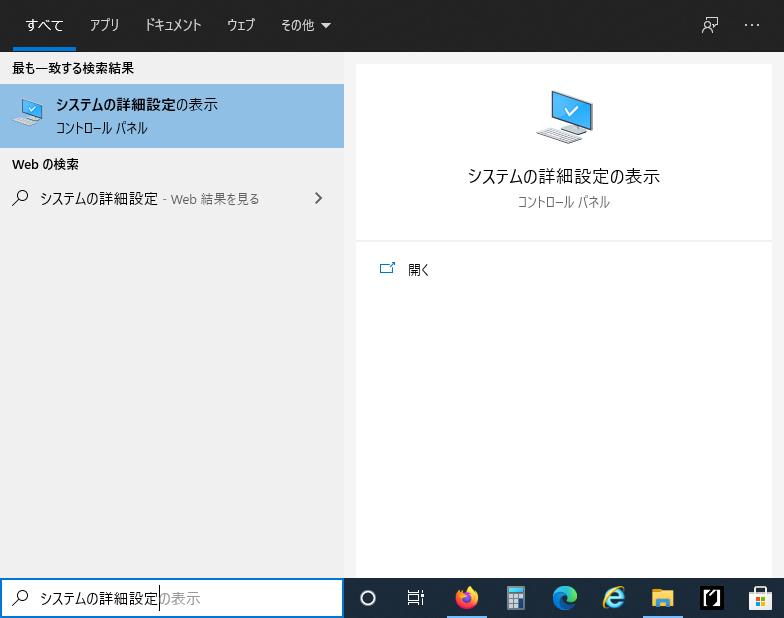
Windows10の場合は、まずスタートボタン隣の検索窓で『システム詳細設定の表示』と検索、表示されたプログラムを実行します。
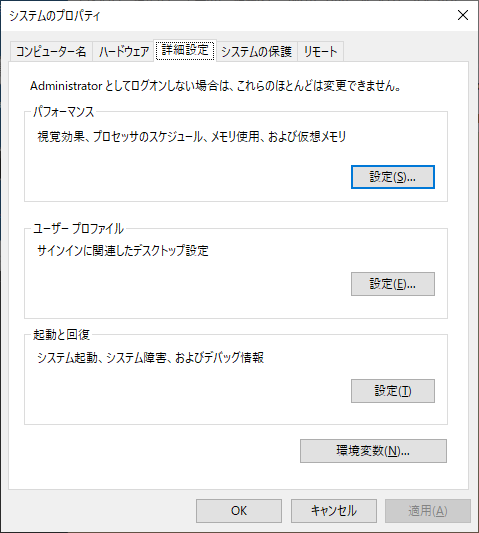
『システムのプロパティ』ダイアログの『詳細設定』タブが表示されるので、下の方にある『環境変数』のボタンをクリックします。
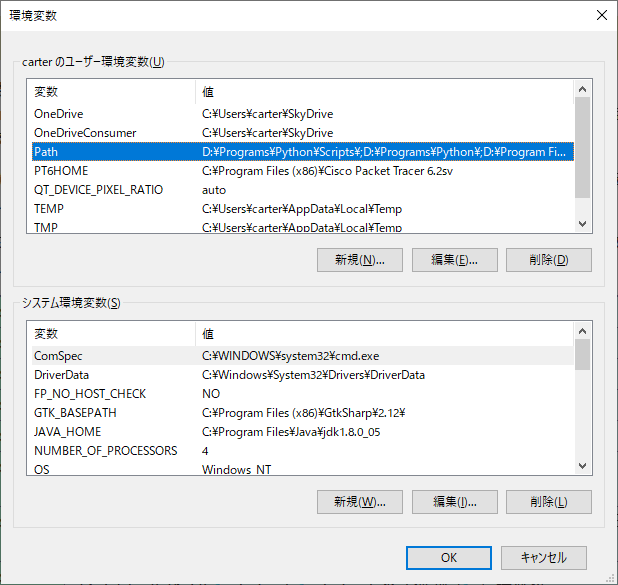
『上の「○○(ユーザ名)の環境変数の中で『Path』を探して選択し、『編集』をクリックします。
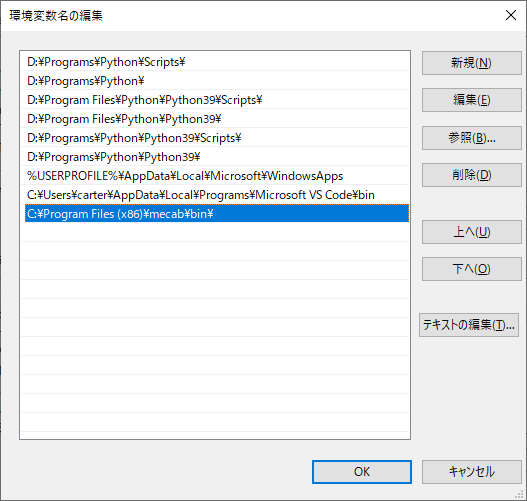
『新規』ボタンをクリックするか、または下の方の空いているあたりをダブルクリックして、MeCabのインストールディレクトリ内の\bin ディレクトリを指定します。
デフォルトでは『C:\Program Files (x86)\mecab\bin\』です。
入力が終わったら『OK』をクリックします。
これでできあがりです。
動作確認
コマンドプロンプトを起動して、mecab と入力してみましょう。
mecab のインストール及び PATH の設定に成功していれば、入力待ちになります。
何か適当に日本語の文を入力してみましょう。
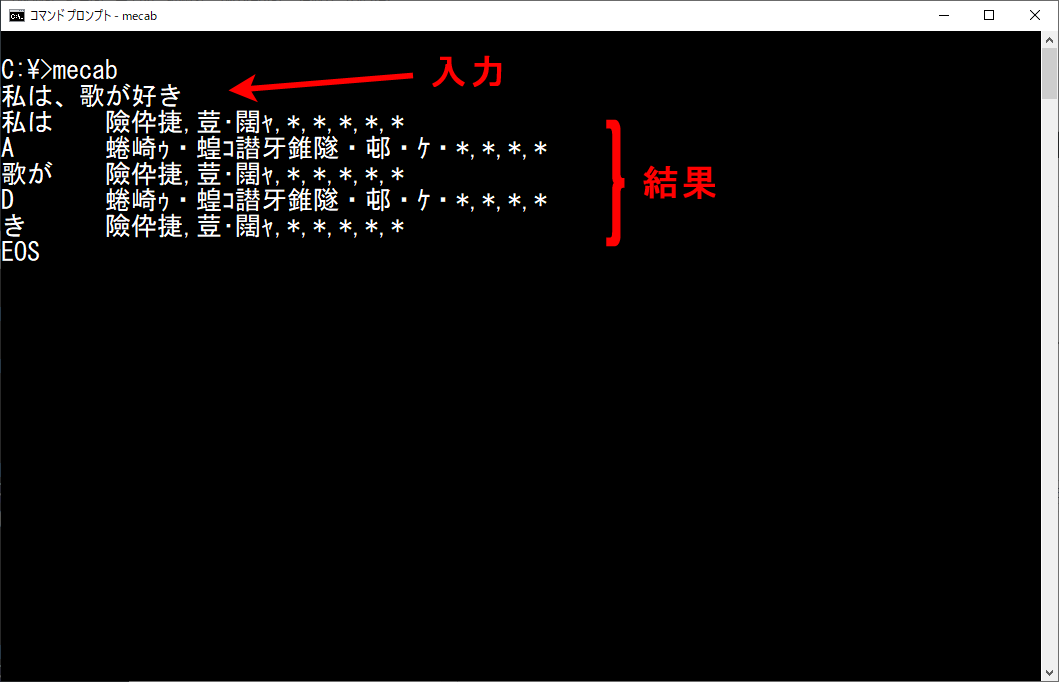
コマンドを入力したすぐ次の行の『私は、歌が好き』が入力した文です。その下の行から解析結果が表示されていますが、インストール時に文字コードとしてShift-JIS以外を指定すると、このように派手に文字化けします。Pythonから利用すると化けませんので安心して下さい。
まぁ、MeCabが動作していることだけはこれで確認できます。
入力された文の解析が終わってもMeCabは終了せず、次の文の入力待ちになります。MeCabを終了するには ctrl + C を入力します。
このままではキモチワルイという場合は、一時的にコマンドプロンプトの表示文字コードをUTF-8にして試してみると良いでしょう。文字コードの変更には、
chcp 65001というコマンドを使用します。
表示文字コードを変えた場合、キーボードから直接文を入力するとなぜかうまく動作しません。
echo コマンドを使ってパイプで mecab に解析したい文を渡してみましょう。
echo 私は、歌が好き | mecab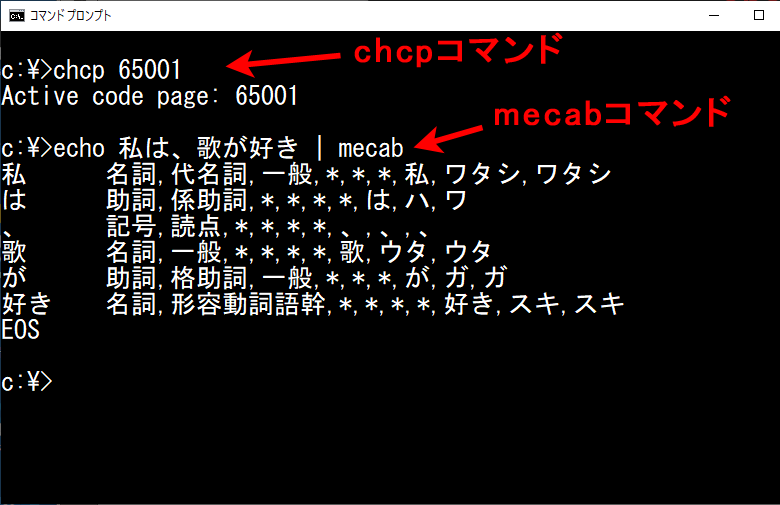
今度はちゃんと文字化けせずに結果が表示されました。
これでMeCabの動作確認は終了です。
mecab-pythonのインストール
python から MeCab を利用するためのモジュールとして mecab-python というものがあるようなので、これをインストールします。
C:\> py -m pip install mecab-python
Collecting mecab-python
Downloading mecab-python-1.0.0.tar.gz (1.3 kB)
Collecting mecab-python3
Downloading mecab_python3-1.0.4-cp39-cp39-win_amd64.whl (511 kB)
|████████████████████████████████| 511 kB 2.2 MB/s
Using legacy 'setup.py install' for mecab-python, since package 'wheel' is not installed.
Installing collected packages: mecab-python3, mecab-python
Running setup.py install for mecab-python ... done
Successfully installed mecab-python-1.0.0 mecab-python3-1.0.4
C:\>あちこち観て回ると、MeCab関係のdllをPythonのインストールディレクトリにコピーするなどいろいろ作業が紹介されているのですが、そんなことをしなくても MeCab のインストールディレクトリに PATH が通っていれば動作するようです。
はじめての構文解析プログラム
サンプルプログラム その1
MeCabで形態素解析を行うもっとも基本的なプログラムです。驚くほど短いです。
import MeCab
tagger = MeCab.Tagger()
result = tagger.parse("私は、歌が好き")
print(result)コード解説
import MeCabPython で MeCab を使用するには、MeCab モジュールをインポートします。
tagger = MeCab.Tagger()
result = tagger.parse("私は、歌が好き")MeCab のもっとも基本的な使い方は、
MeCab.Tagger() メソッドで生成したオブジェクトを使って、
parse() メソッドで引数に指定した文字列を解析する
です。
MeCab.Tagger() は、Taggerクラスのオブジェクトを返します。解析を行うparse()などのメソッドはTaggerクラスのメソッドです。
MeCab.Tagger() の引数は、コマンドラインで mecab コマンドを使用するときのコマンドラインオプションをそのまま指定するようです。
mecabのコマンドラインオプションは以下の通りです(mecab –helpで表示)
-r, –rcfile=FILE use FILE as resource file
-d, –dicdir=DIR set DIR as a system dicdir
-u, –userdic=FILE use FILE as a user dictionary
-l, –lattice-level=INT lattice information level (DEPRECATED)
-D, –dictionary-info show dictionary information and exit
-O, –output-format-type=TYPE set output format type (wakati,none,…)
-a, –all-morphs output all morphs(default false)
-N, –nbest=INT output N best results (default 1)
-p, –partial partial parsing mode (default false)
-m, –marginal output marginal probability (default false)
-M, –max-grouping-size=INT maximum grouping size for unknown words (default 24)
-F, –node-format=STR use STR as the user-defined node format
-U, –unk-format=STR use STR as the user-defined unknown node format
-B, –bos-format=STR use STR as the user-defined beginning-of-sentence format
-E, –eos-format=STR use STR as the user-defined end-of-sentence format
-S, –eon-format=STR use STR as the user-defined end-of-NBest format
-x, –unk-feature=STR use STR as the feature for unknown word
-b, –input-buffer-size=INT set input buffer size (default 8192)
-P, –dump-config dump MeCab parameters
-C, –allocate-sentence allocate new memory for input sentence
-t, –theta=FLOAT set temparature parameter theta (default 0.75)
-c, –cost-factor=INT set cost factor (default 700)
-o, –output=FILE set the output file name
-v, –version show the version and exit.
-h, –help show this help and exit.
この中で、Pythonから使用する場合によく指定されるのは、
使用する辞書を指定する -d や -u オプション
出力の型式を指定する -O オプション
だと思います。
このサンプルでは、オプションなしで実行しています。
Tagger.parse() メソッドは、引数で指定した引数の形態素解析を行います。結果は、コマンドラインで実行した際に表示される結果と同じ書式の文字列で返されます。
実行結果
C:\> python mecabtest1.py
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
歌 名詞,一般,*,*,*,*,歌,ウタ,ウタ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
EOSこのように表示されます。
parse()メソッドの返却値は全体が連続したテキストのため、解析結果をプログラムで利用する場合は改行・タブ・カンマを目印に split() メソッドなどで切り分ける必要があるでしょう。
サンプルプログラム その2
その1よりほんのすこしだけ複雑なプログラムです。
import MeCab
tagger = MeCab.Tagger()
node = tagger.parseToNode("好きなことを頑張ることに、おしまいなんてあるんですか?")
while node:
print(node.surface, "\t", node.feature)
node = node.nextコード解説
node = tagger.parseToNode("好きなことを頑張ることに、おしまいなんてあるんですか?")サンプルプログラムその2では、形態素解析にparseToNode() メソッドを使用します。解析したい文を引数にするのは parse()と同じですが、返却値は各形態素を表すNode型のオブジェクトです。Node型オブジェクトはリンクリスト(各データが自分の次のデータを指し示て数珠つなぎ状のデータ構造)になっており、元の文に登場する順に形態素=Node型オブジェクトが並んでいます。parseToNode()メソッドは、文の先頭の形態素を返します。
while node:
print(node.surface, "\t", node.feature)
node = node.next
最初の while node は『まだNode型オブジェクト(形態素)があるなら』を表します。node は現在注目している形態素を指していますが、文中最後の形態素の次は None となります。
print()では、node.surface と node.feature を表示しています。
node.surface はその形態素の表層形(文中に登場した形)、
node.feature はその形態素の解析結果を表します。
この例では形態素ごとに切り分けたオブジェクトになっていますが、解析結果は一続きのテキストなので、解析結果をプログラムで利用するにはカンマを目印に split() する必要があるでしょう。
なお、並んでいる情報は、
品詞, 品詞細分類1, 品詞細分類2, 品詞細分類3, 活用型, 活用形, 原形, 読み, 発音
のようです。それぞれが具体的に何を表しているのかは結果例を参考にして下さい。
node.next は、リンクリストで繋がった次のオブジェクト、つまり文中で次の登場する形態素を表しています。よって、 node = node.next では注目する形態素を次に進めています。もし現在注目しているのが最後の形態素だった場合、その次の値は None となり、Whileループが終了します。
実行結果
C:\> python mecabtest2.py
BOS/EOS,*,*,*,*,*,*,*,*
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ
こと 名詞,非自立,一般,*,*,*,こと,コト,コト
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
頑張る 動詞,自立,*,*,五段・ラ行,基本形,頑張る,ガンバル,ガンバル
こと 名詞,非自立,一般,*,*,*,こと,コト,コト
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
、 記号,読点,*,*,*,*,、,、,、
おしまい 名詞,一般,*,*,*,*,おしまい,オシマイ,オシマイ
なんて 助詞,副助詞,*,*,*,*,なんて,ナンテ,ナンテ
ある 動詞,自立,*,*,五段・ラ行,基本形,ある,アル,アル
ん 名詞,非自立,一般,*,*,*,ん,ン,ン
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
? 記号,一般,*,*,*,*,?,?,?
BOS/EOS,*,*,*,*,*,*,*,*このように、一瞬で解析できます。
まとめ
というわけで、例によって突然思い立って MeCab をインストールしました。形態素解析ができるようになれば、自然言語による対話システムや翻訳システムなど様々な応用への道が開けます。まぁ実は…このあと何をやるか、まだ考えていないんですが…。

コメント