
今回は日本語の係り受けの解析ができるエンジン、CaboCha を Python から使ってみます。
インストール
CaboChaのインストール
CaboChaは内部で MeCab を使用するようなので、事前に MeCab がインストールされている必要があります。別記事を参照してインストールしておいて下さい。
CaboCha は MeCab と同じ作者による日本語係り受け解析エンジンです。MeCabと同じくオープンソースで、フリーで使用することができます。公式サイトはこちら
ダウンロード&インストール
CaboCha をインストールするには、まず公式サイト内のダウンロードページから、インストール用の .exe ファイルをダウンロードします。2021年10月現在の最新版は cabocha-0.69.exe です。2015年より更新されていないようです。
ダウンロードしたファイルを実行してインストールします。
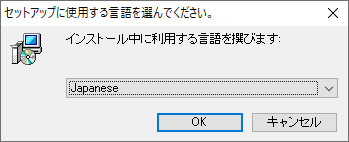
まずインストールウィザードで使用される言語を選択します。デフォルトは『Japanese』です。
『次へ』をクリックします。
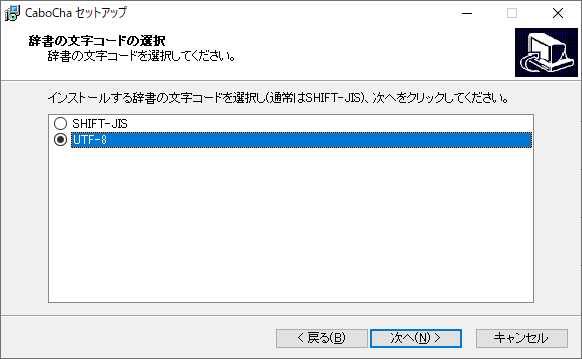
辞書の文字コードを選択肢します。デフォルトは Shift-JIS ですが、Python から使用する場合は UTF-8 にします。
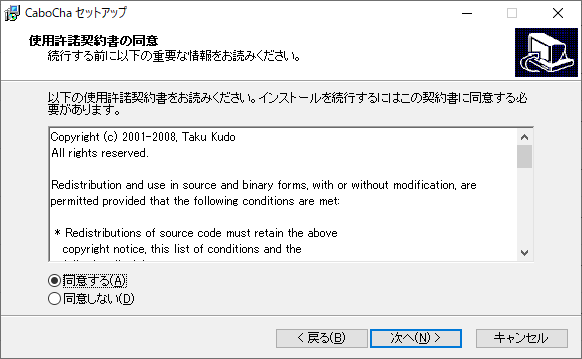
使用許諾契約書に目を通し、『同意する』にチェックを入れて『次へ』をクリックします。
インストール先のディレクトリを指定します。デフォルトは C:\Program Files (x86)\CaboCha になっています。後で艦橋変数を設定するのに使用するのでメモしておいて下さい。
スタートメニューに登録されるショートカットの名前を指定します。
最終確認です。『インストール』をクリック。
ファイルのコピーが始まります。
管理者権限のあるユーザで実行していると、このダイアログが表示されます。
まぁどちらでもお好みで。
続いて辞書がセットアップされます。
インストールウィザードとは別にコマンドプロンプトが開き、辞書のセットアップが行われます。手元の環境では2分ほどかかりました。
これでインストールは終了です。『完了』をクリックしてウィザードを終了します。
環境変数の設定
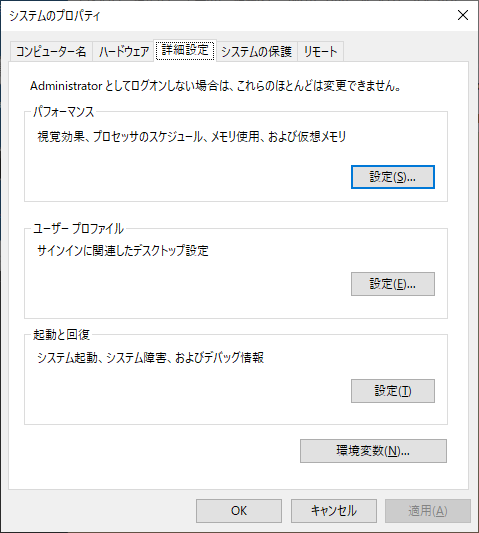
コントロールパネル→システム→システムの詳細設定
[Windows]キー+[Pause/Break]キー →システムの詳細設定
スタートボタン右クリ→システム→システムの詳細設定
『システムの詳細設定の表示』を検索
などして『システムの詳細設定』を表示し、一番下の『環境変数』をクリックします。
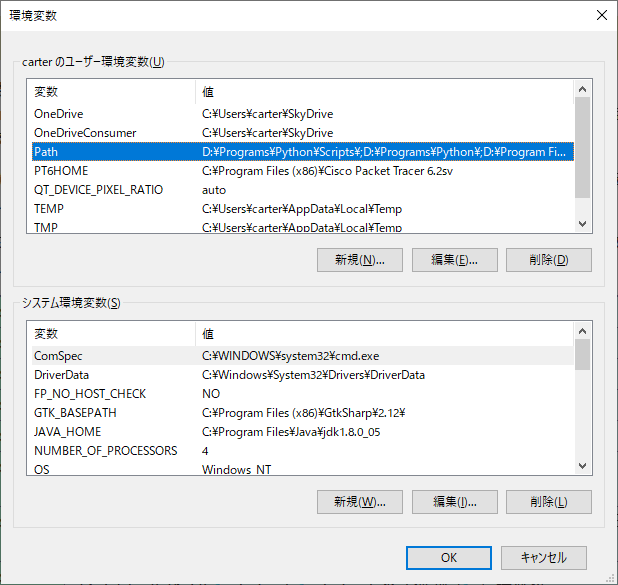
『上の「○○(ユーザ名)の環境変数の中で『Path』を探して選択し、『編集』をクリックします。
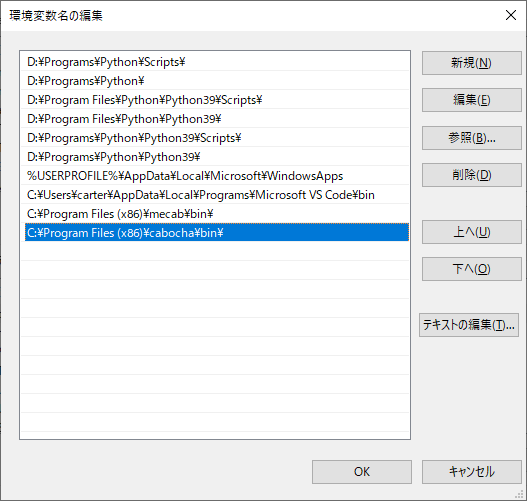
『新規』ボタンをクリックするか、または下の方の空いているあたりをダブルクリックして、CaboCはのインストールディレクトリ内の\bin ディレクトリを指定します。
デフォルトでは『C:\Program Files (x86)\cabocha\bin\』です。
入力が終わったら『OK』をクリックします。
これで艦橋変数の設定は終了です。
動作確認
インストールができたら、コマンドプロンプトから動作確認してみます。
辞書の文字コードを UTF-8 に変更したので、まずコマンドプロンプトでUTF-8の文字を表示できるように
chcp 65001を実行します(画面がクリアされて『Active code page 65001』と表示されます)。
mecab と同様に、echo コマンドとパイプを使って cabocha コマンドに解析したい文を渡します。
echo 私は、歌が好き | cabocha -f2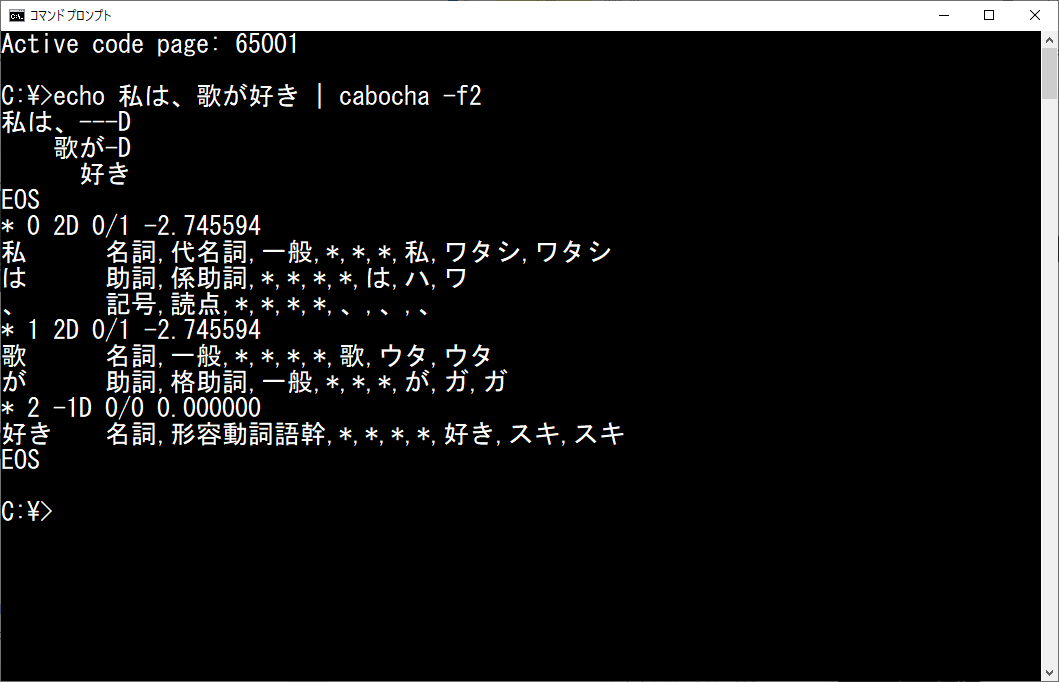
このように表示されれば成功です。ちなみに cabocha コマンドのオプション -f2 は結果表示の形式を指定するものです。
cabocha-pythonのインストール
ここで問題が発生しました。MeCab の時は問題にならなかったのですが、CaboCha を Python から利用するためのモジュール、cabocha-python は Python 3.9.6(64bit版)の環境にはインストールできないようです。いろいろ試したところ、Python 3.8.5 の 32bit版ではすんなりインストールできましたが、それより新しいバージョンは 32bit版、64bit版のいずれでも『Visual C++ 14以上が必要』というエラーが表示され先に進めなくなってしまいました。うちの環境には『Visual C++ 14以上』を含む Visual Studio 2019 がインストールされているのですが…。
幸い、Pythonランチャーがあれば異なるバージョンのPythonを同時にインストールすることも可能なので、CaboCha関係の実験を行う場合のみ Python 3.8.5 の32bit版を使用することにします。
なお、Python3.8.5 の32bit では、こちらの記事の手順で MeCab-python のインストールができなくなってしまったのですが、py -m pip install mecab (mecab-pythonではなく)ならばインストールできました。別物のモジュールのようなのですが、こちらの記事のサンプルプログラムその1~3は動きます。また、Pythonから 直接 MeCab が使えなくても、CaboCha用のメソッドで形態素解析は可能です。
Pythonでのcabocha用モジュールのインストールには、
py -m pip install cabocha-python コマンドを使用します。
C:\>py -m pip install cabocha-python
Collecting cabocha-python
Downloading cabocha_python-0.69.1-cp38-cp38-win32.whl (484 kB)
|████████████████████████████████| 484 kB 3.2 MB/s
Installing collected packages: cabocha-python
Successfully installed cabocha-python-0.69.1
C:\>というわけで、最終的に『日本語解析』の実験環境は以下のようになりました。
Windows 10 Home (64bit版)
Python 3.8.5 (32bit版)
MeCab 0.996 (32bit版) ※MeCabの公式配布は32bit版のみです
CaboCha 0.69 (32bit版) ※CaboChaの公式配布は32bit版のみです
mecab(pythonモジュール)0.996.3
cabocha-python(pythonモジュール)0.69.1
CaboChaで係り受けを解析するプログラム
サンプルプログラム その1
CaboChaで係り受けを解析する、もっとも基本的なプログラムです。
import CaboCha
parser = CaboCha.Parser()
tree = parser.parse("私は、歌が好き")
print(tree.toString(CaboCha.FORMAT_TREE_LATTICE))コード解説
import CaboChaCaboCha で構文解析を行うためには、CaboCha モジュールをインストールします。
parser = CaboCha.Parser()CaboCha.Parser() は、構文解析を行う Parserクラスのオブジェクトを生成します。
tree = parser.parse("私は、歌が好き")Parser.parse(文字列) は、引数で与えられた文の解析を行い、結果をTree型のオブジェクトとして返します。
print(tree.toString(CaboCha.FORMAT_TREE_LATTICE))Tree.toString() メソッドは、解析結果の Treeオブジェクト の内容を文字列に変換します。toString() メソッドの引数として定数 Cabocha.FORMAT_TREE_LATTICE を与えていますが、これはコマンドラインで -f2 オプションを指定したのと同じく、ツリー(後の結果例の前半)と lattice(後の結果例の後半)の両方を文字列化します。
toString() の結果はひとつづきの文字列なので、この結果をさらにプログラムで利用するためには改行やタブやカンマを目印に split() で分割する必要があります。が、そもそも toString() で文字列化してしまうのではなく、次のサンプルプログラムその2のようにする方が簡単でしょう。toString() は手っ取り早く表示をするのにむいています。
実行結果
私は、---D
歌が-D
好き
EOS
* 0 2D 0/1 -2.745594
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
* 1 2D 0/1 -2.745594
歌 名詞,一般,*,*,*,*,歌,ウタ,ウタ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
* 2 -1D 0/0 0.000000
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
EOSインストール後の動作テストと同様の結果が表示されます。前半に文を文節に区切り、係り受けを視覚的に表したツリー状の表示が、後半に詳しい分析結果が表示されています。
後半では、チャンク(≒文節)ごとに
* 0 2D 0/1 -2.745594
のような表示があり、さらにチャンクを形態素(≒単語)ごとに区切ってMeCabと同様に品詞などが表示されます。
チャンクごとの表示の書式は、
* チャンク番号 係り先のチャンク番号 主辞/機能語の位置 係り関係のスコア
となっています。たとえば上の実行結果では、『私は』と『歌が』の両方の係り先の文節が、チャンク番号2の『好き』であることなどが読み取れます。
サンプルプログラム その2
次に、サンプルプログラム その1 では toString() で一続きの文字列に変換してしまっていた部分のうち、後半の lattice を自力で表示するプログラムです。
import CaboCha
parser = CaboCha.Parser()
tree = parser.parse("私は、歌が好き")
chunk_no = 0
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
chunk = token.chunk
print("* %d %dD %d/%d %f" % (chunk_no, chunk.link, chunk.head_pos, chunk.func_pos, chunk.score))
chunk_no += 1
print(token.surface, "\t", token.feature) コード解説
for i in range(tree.size()):
token = tree.token(i)
# 中略
print(token.surface, "\t", token.feature)Tree型オブジェクトは、文を構成する形態素が順に並んだ構造です。mecab-python の Node型オブジェクトと異なり、リンクリストではなく配列のように番号を用いてアクセスします。
tree.size() は、Tree型オブジェクト tree に含まれる形態素の数を取得します。各形態素は、文中に登場する順に 0 ~ 形態素数-1 の番号が振られています。この例ではすべての形態素に順にアクセスするため、
for i in range(tree.size()):としてループしています。
token = tree.token(i)とすると、Tree型オブジェクト tree から『i 番目の形態素』を表す Token型オブジェクトを取得することができます。
print(token.surface, "\t", token.feature)の部分から判るように、Token型オブジェクトはmecab-pythonでのNode型オブジェクトと同様、
Token.surface がその形態素の表層形(文中に登場した形)、
Token.feature がその形態素の解析結果(mecabと同じ型式)
を表します。
さらにToken型オブジェクトが チャンク に関する情報も保持しています。
チャンク とは『かたまり』のことで、分野や文脈によって具体的になにを表すのかが異なるのですが、ここでは日本語文法の『文節』に相当する『形態素のかたまり』のことです。
チャンクの最初の形態素であるToken型オブジェクトでは、Token.chunk フィールドにそのチャンクに関する情報を表すChunk型オブジェクトが入っています。
チャンクの最初以外の形態素では Token.chunk は None です。
よって、
if token.chunk:
chunk = token.chunk
print("* %d %dD %d/%d %f" % (chunk_no, chunk.link, chunk.head_pos, chunk.func_pos, chunk.score))として、token がチャンク先頭の場合のみチャンク情報の表示を行っています。
Chunk型のフィールドは、
link 係り先のチャンク番号。係り先がない場合は-1
head_pos 主辞の位置(このチャンク中で何番目の形態素か)
func_pos 機能語の位置(このチャンクの中で何番目の形態素か)
score 係り関係のスコア
となっているようです。
※くどいですが、だいたいチャンク=文節、形態素=単語 に対応します。
さらに、この例では使用していないフィールドとして、
token_size このチャンクに含まれる形態素数
token_pos このチャンクは先頭から何番目の形態素から始まるか
などがあります。
なお、困ったことに Chunk型自身にもTree型にもチャンク番号のフィールドがありませんので、
chunk_no = 0
for i in range(tree.size()):
# 中略
if token.chunk:
# 中略
chunk_no += 1として、Tree型の中で何番目に出てきたチャンクかを変数chunk_noで数えてチャンク番号としています。
※toString() のソース(C++)を見ても、ローカル変数で数えていました…
実行結果
* 0 2D 0/1 -2.745594
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
* 1 2D 0/1 -2.745594
歌 名詞,一般,*,*,*,*,歌,ウタ,ウタ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
* 2 -1D 0/0 0.000000
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキこのように分析結果を表示することが出来ます。
サンプルプログラム その3
ちょっと応用して、チャンクの係り受けを判りやすく表示するプログラムを作ってみました。
import CaboCha
parser = CaboCha.Parser()
tree = parser.parse("私は、歌が好き")
# チャンクを表示
def chunkToString(chunk, tree):
chunk_surface = ""
for i in range(chunk.token_pos, chunk.token_pos+chunk.token_size):
chunk_surface += tree.token(i).surface
return chunk_surface
# チャンクのリストを作成
chunk_list = []
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
chunk_list.append(token.chunk)
# 係り受けの表示
for i in range(len(chunk_list)):
chunk = chunk_list[i]
if chunk.link>=0:
print(chunkToString(chunk, tree), "->", chunkToString(chunk_list[chunk.link], tree))
else:
print(chunkToString(chunk, tree))
コード解説
def chunkToString(chunk, tree):
chunk_surface = ""
for i in range(chunk.token_pos, chunk.token_pos+chunk.token_size):
chunk_surface += tree.token(i).surface
return chunk_surface関数 chunkToString は、チャンク単位で文字列化しています。
原理は簡単で、位置 token_pos から token_size 個だけToken(形態素)を辿って、Token.surface を連結しています。
chunk_list = []
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
chunk_list.append(token.chunk)チャンク番号とチャンクの対応をchunk_listに格納しています。Tokenを辿って、Chunkを見つけるたびにchunk_listに追加しているだけです。
チャンク番号は、ようは『Treeの中で(最初を0番目として)何番目に登場するchunkか』ということなので、リストに順次appendしていけば配列の添字がそのままチャンク番号となります。
for i in range(len(chunk_list)):
chunk = chunk_list[i]
if chunk.link>=0:
print(chunkToString(chunk, tree), "->", chunkToString(chunk_list[chunk.link], tree))
else:
print(chunkToString(chunk, tree))前の部分で作ったchunk_listを辿ってチャンクごとに表層形で表示し、係り先があれば(chunk.link≧0ならば)係り先のチャンクを “->” に続けて表示しています。
実行結果
例:『私は、歌が好き』
私は、 -> 好き
歌が -> 好き
好きこのように、視覚的に判りやすく表示できます。
もう少し複雑な文で試してみましょう。
例:『好きなことを頑張れることに、おしまいなんてあるんですか?』
parser.parse() の引数の文をいろいろ変えてみました。
好きな -> ことを
ことを -> 頑張れる
頑張れる -> ことに、
ことに、 -> あるんですか?
おしまいなんて -> あるんですか?
あるんですか?国語の成績がイマイチだった人間がいうのもアレですが…ちゃんと解析できていると思います(汗
例:『裏庭には二羽、庭には二羽、鶏がいます』
裏庭には -> 二羽、
二羽、 -> います
庭には -> います
二羽、 -> います
鶏が -> います
います『庭には -> います』なら『裏庭には -> います』のような気もしますが…。まぁだいたいあっていると思います。
まとめ
インストールにはちょっと苦労しましたが、非常に面白く、可能性の広がる環境が出来上がったと思います。このシリーズはプログラムが複雑になりそうなので、次がいつになるかは判りませんが…。

コメント