
人の声の再生速度を変更
さて、前回の再生速度変更プログラムを使って、言葉を速く/遅くしてみましょう。
元データは以前も使ったこちら。
※この音声は『VOICEVOX』というソフトウェアを使用して作成しました。サイトはこちら
※音声ライブラリは『VOICEVOX:四国めたん』を使用しています。
再生速度を上げる
それでは、まず早回しから。元の2倍にしています。
元の音声と高さが変わらないまま、速度が2倍になっています。これは上手くいっているようです。
再生速度を下げる
今度はスロー再生。まずは元の1/2にします。
また音量が細かく増減してしまってフラッタノイズのようになっています。
さらにゆっくり、1/5を試してみました。
なかなか酷いです(苦笑)。言葉が聞き取りづらいレベル。
症状は、クロスフェード実装・位相探索を実装しない段階のものと似ているのですが、位相の探索範囲やクロスフェードの幅などをいじっても改善しませんでした。
言葉の波形を見る
この原因を探るため、この元音声の波形全体を観察してみます。
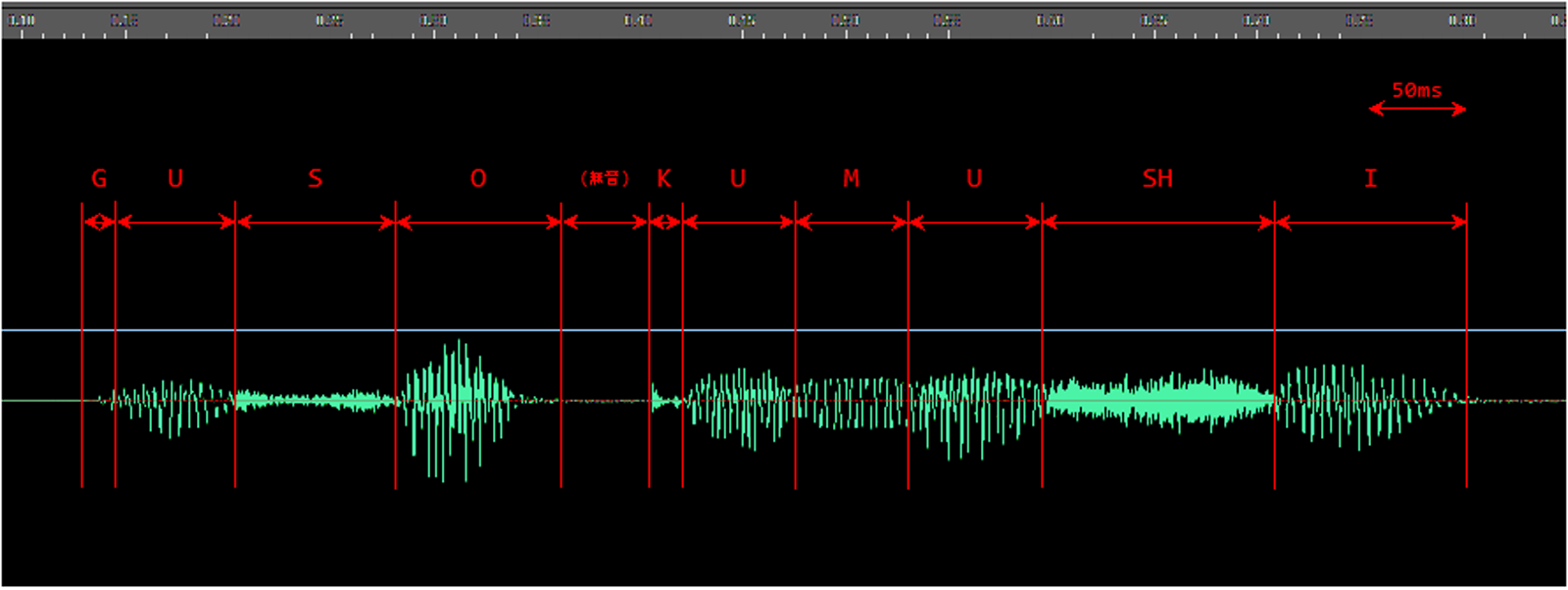
音節は『ぐ・そ・く・む・し』の5つ、そしてそれぞれが子音部と母音部に別れていることが判ります。『K』の前には短い無音部分があり、これを含めて全体が11の部分に別れています。
『ぐそくむし』という単語の発音にかかっている時間は約1秒なので、平均すると1音節は200msほどのはずです。耳で聞くと各音節の時間が大きく違うようには聞こえないのですが、波形を見るとそれぞれの音にかかっている時間は大きく異なります。たとえば子音『G』音や『K』音は短く、30msほどしかありません。同じ子音でも『S・SH』音は長く、120~150msも続いています。母音は子音ほどのばらつきはなくどれも100~150msですが、その間に大きな音量の変化があり、一定の波形が続いているわけではありません。
まず注目すべきは短い子音です。G音やK音は非常に短く、50msの『窓』の範囲にすっぽり入ってしまうことが判ります。このため、スローで再生しようとすると子音が何度もコピーされて、『く』の発音が『KKKKU』のようになってしまうのです。
また母音の音量の変化も問題です。母音はそれぞれ『窓』の幅50ms以上の長さではありますが、その間に大きな音量の変化(ほとんどの場合、発音の始まりの部分で音量がだんだん大きくなり、終わりの部分で音量がだんだん小さくなる)があります。この音量の変化の部分を何度も繰り返しコピーしてしまうため、長音と言うよりは短い母音を連続して何度も発音しているような波形になってしまいます。
以上により、期待したような『ぐーーそーーくーーむーーしーー』という音にならずに、
『GGGGUGUUU SSSSOSOOO KKKUKUKUKUUU MMMMUMUUU SHSHSHISHIII』
という感じになってしまうのです。
子音の種類(参考)
『K』音は舌で息の流れを一時完全に停止して、それが開放される瞬間に発音されます。子音の前に無音の状態があり、子音発音の直前にならないと声帯が振動しません。このような音を『無声破裂音』といいます。舌ではなく唇で息の流れを停止した場合は『P』音になります。
声帯が振動した状態で同じように舌や唇を動かすのを『有声破裂音』といいます。舌だと『G(g)』音、唇だと『B(b)』音や『V(v)』になります。
舌や喉、唇で息の通る道を狭めて、空気の流れる音を発するものを摩擦音といいます。そのうち、子音発生中に声帯の振動がとまっているものを無声摩擦音といいます。舌で発音するのが『S(s)』音や『SH(ʃ)』音や『ch(ç)』音、喉で発音するのが『H(h)』音、唇で発音するのが『F(f)』音です。摩擦音は破裂音と違って音を持続することができ、実際に長時間発音していることが『ぐそくむし』の発音からも観察できます。『S』や『SH』の部分を単独で引き延ばすと、声帯の振動を伴わない、ホワイトノイズのような音が持続していることが判ります。
声帯が振動した状態で摩擦音を出す物を有声摩擦音といいます。日本語で該当するものは、舌で摩擦音を発する『J(ʒ)』音や『Z(z)』音です。
子音には他にもいろいろな種類があり、またカナ表記が同じになっても言語によって・単語の先頭か途中の音かによって声帯の振動のタイミングが変わったりして複雑です。本格的な音声発生や音声認識のプログラムを作る場合には、そのあたりをちゃんと調べる必要があるかもしれません。
では、どうすればよいか。
短い子音や母音の音量変化が繰り返しコピーされるのがノイズの原因だとすれば、各音節に較べて相対的に窓の幅を小さくすることでノイズを目立たなくすることができそうです。そこで、低周波数成分の再生を諦め、窓の幅を50msより小さくすることにしました。
では、どこまで小さくするか。
人間の可聴周波数範囲は20~20,000Hzといわれています。しかしこれは耳の良い人の話で、実際に誰でも聞き取れるのは35~10,000Hzくらいだと思われます。
※ちなみに高音域が加齢とともに聞こえなくなる、というのは有名な話です。
※低音域は生まれつき聞こえない人は聞こえないそうです。ただし『聞こえない』といっても『音が鳴っていることが判らない』のではなく、『ブー』という連続した音の代わりに『タタタタ…』という個別の振動として感じてしまうのです。むしろ時間方向の分解能が普通の人よりよい、と言うべきかも。
というわけで、窓の幅を半分の25msにしてみました。これなら一番短い『K』音の発音時間より短くなるので、状況が改善しそうです。またこの窓サイズでは1/25ms=40Hz以下の周波数成分は再現できないのですが、人間の声の基本周波数は男性の低い声でも100Hzくらいはあるので、40Hz以下をカットしても言葉は聞き取れるはずです。
40Hz以下の周波数成分は再生できなくなっているはずですが、むしろ言葉はずっと聞き取りやすくなったと思います。音質も悪くなった気はしません(そもそもこのサンプル音声はもともと40Hzより低い成分を含んでいないとも考えられます)。
よく聴くと低いブーンというノイズが乗っているように聞こえます。たぶん40Hzの断続が『ブーン』という音が被っているように認識されるのでしょう。ただ『窓』の幅が50msの場合よりも振幅の変化が小さく抑えられているはずなので、それほど気にならないと思います。
さらに窓のサイズを小さく、10msにしてみましょう。これだと100Hz以下の成分が破壊されてしまいます。サンプルは女性の声なので母音の基本周波数はもっと高いのですが、どうなるでしょうか?
かえって音質が悪くなってしまいました。100Hzの断続が声の周波数に近くなって無視できなくなったのと、摩擦音や破裂音の周波数範囲が広く、100Hz以下のカットが影響を与えてしまっているのかもしれません。
人の声以外の実在音では。
今回は『言葉が聞き取れれば良い』ということで窓の幅を25msにしましたが、音楽の場合はどうでしょうか?
ちょっと調べたところ、ピアノの最低音が27.5Hz、コントラバス(オーケストラで一番低い音を出す楽器)の最低音が41Hzなのだそうです。先ほど実験した25msでは、コントラバスの音はギリギリ再現できますがピアノの低い方から7個ほどの鍵盤の音は再現できません。その範囲が再現できないと曲が成立しないならば窓のサイズを1/27.5≒37ms程度まで大きくする必要がありますが、そうすると今度は人の声が不自然になってしまいます。
目的に応じて調整するしかないようです。
おまけ(逆回し再生)
波形の観察で判ったように、言葉全体の波形を見ると子音と母音は別の音として並んでいます。よって、波を時間方向に逆転(テープメディアの逆回し再生)すると、
『ぐ・そ・く・む・し』→『し・む・く・そ・ぐ』
とはならず、
『G・U・S・O・K・U・M・U・SH・I』→『I・SH・U・M・U・K・O・S・U・G』
のような音の並びとなるため、『イシュムコス』と聞こえます(最後のGは後に母音がないため聞き取れません)。
import numpy
import os
import wavfile
f = wavfile.readfile("input.wav") # 元のwavファイルの名前をここで指定する
src = f["ldata"]
dst = src[::-1] # サンプリングデータの並びを反転
wavfile.writefile(numpy.array([dst]), "output.wav", samplingfreq=f["samplingfreq"]) # 変換後のファイルの名前をここで指定する
まとめ
以上で、『音の高さを変えずに再生速度変更』は一応の完成、ということにします。本格的にやるには短い区間毎にフーリエ変換するなどしてしっかり波形を分析するのがよさそうですが、まぁ思いつきでプログラムを作ったわりにはそこそこの音質で再生速度変更ができたと思います。
次は、アレをやってみたい…

コメント